vmstat - サーバー管理でよく使うコマンド
CPUの利用状況、ディスクIOの状況をリアルタイムに表示します
■よく使う形(例)
# vmstat 5

データベースを使用したシステム運用をしている場合は、頻繁に使うコマンドです。
負荷が高くなった場合、このシステムのネックがディスクなのか、CPUなのかメモリなのかを判断するに非常に役に立ちます。
vmstatはたまに実行してみるのではなく、絶えず運用しているサーバーの場合は、毎日ウォッチすることをお勧めします。
ずっと見ていることで、予想外の負荷を見つけ出すことができます。
コマンドを終了する場合は、Ctrl+c
■出力データの見方
| 計測値 | 意味 | コメント | |
|---|---|---|---|
| procs | r | CPU へのアクセスを待っているプロセスの数 | r,b とも平常時はどちらも 0~2,3を移動するくらいなもの。 b の値が定常的に多くなると、ディスク性能の問題か、想定以上のディスクIOが繰り返されている可能性が有るかも。 とにかく恒常的に数値が上がる場合は、早急にその原因をつきとめる必要あり。 |
| b | 入出力待ちでスリープ状態にされているプロセス数 | ||
| memory | swpd | 仮想メモリ量 | 割り当てられるディスクメモリ量を表示しているが、この数字だけでは何も分からないかも。 free で表示される空きメモリ量も割り当てで残ったメモリ量のことで、実際にはもっと空きメモリが存在する。 筆者はあまり見ていない。(笑) |
| free | 空きメモリ量 | ||
| buff | バッファに使用されているメモリ量 | ||
| cache | ページキャッシュとして使用されているメモリ量 | ||
| swap | si | ディスクからスワップインしたディスクメモリの量 | 物理メモリが足りていれば、これらの数値はあまり上がらないはず。というかほとんどが 0 になっていると思われる。(瞬間的に使われるときがある) swap の値が定常的に高い場合は、物理メモリが不足している可能性が高い。 |
| so | ディスクにスワップアウトしたディスクメモリの量 | ||
| io | bi | ブロックデバイスから受け取ったブロック (blocks/sec) |
大きなファイルの移動(コピー、ダウンロードなど)や、多くのデータをデータベースから読む込むとき(または書き込むときは、大きく数字が上がる。 こ のピーク値はどちらかというと、ハードディスクの性能に関係しているもので、高いからどうのということではないが、高い値が長時間続く場合は、明らかに ディスクIOが頻発し、割り込みも出来ない状態になっているので、ディスクの増設や、サーバーの分散化などを検討する必要があるかも。 |
| bo | ブロックデバイスに送られたブロック (blocks/sec) |
||
| system | in | 毎秒の割り込み回数 | CPU などのリソースをタイムシェアで使っている関係で、複数 のプロセスが動くと当然、切換えが発生する。その割り込み頻度は、プロセスが増えれば増えるほど、割り込みも増えるので、サーバーの負荷が上がるとき は、大体この数字も高くなる。 定常的に高い数値の場合は、負荷耐性も落ちてきていることになるので、システムの見直しが必要かも。 |
| cs | 毎秒のコンテキストスイッチの回数 | ||
| cpu | us | ユーザーが使用したCPUの割合(%) | id(空き) = us(ユーザー利用) + sy(システム利用) システム構成にもよるが、安定的なサーバーだと、大体 90%以上のアイドルがある。 瞬間的に多く消費されるCPU使用は問題ないが、定常的に使用率が高い場合は、負荷耐性も落ちてきていることになるので、システムの見直しが必要かも。 |
| sy | システムが使用したCPUの割合(%) | ||
| id | CPUのアイドル(%) | ||
| wa | IOの待ち時間 | ||
■主なオプション
| オプション | 機能説明 |
|---|---|
| -n | 設定すると、最初だけしかヘッダータイトルを表示しません(オプションなしでは、20行ごとにヘッダータイトルを表示) |
■よくある負荷の状態
○ r が高く、CPU使用率も高い場合
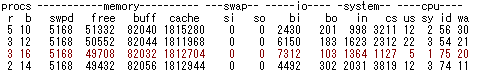
r の数値が高いのは、CPUの処理待ちが多いといった状態です。
明らかにCPUに負荷がかかっているので、CPUのクロック数を上げたり、CPUの数を増やせばそれなりに改善していきます。
ただ、CPUに待ちが生じるのはハードウェア的な処理速度云々より、CPUを効率よく使わないOSやアプリケーションの問題が多いため、まずはソフトウェ ア側から見直すのが先決でしょう。最初からCPUにやさしい設計をしてこなかった場合、ソフトウェアの見直しでかなり劇的に改善されることが多いようです。
上記の例は、データベースのトリガーにロックがかかり、ディスクI/Oまで遅延が発生してしまった例です。(^^;
CPUの数を増やして負荷を下げるのも方法ですが、CPUの数を増しても負荷の高いアプリケーションを動かしたりすると、あまり効果はありません。CPUの数を増すのは並列処理にのみ効果があるので、同時に動作するプロセスが多い場合に検討すればよいと思います。
○ si so が高い場合
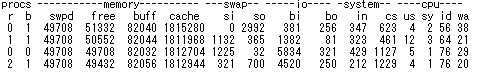
これは単に搭載しているメモリの不足です。
アプリケーションを見直したり、バッチの実行時間をずらしたりと運用で対処することは当然必要ですが、なによりメモリ増設を一番に考えたほうが良いでしょ う。SWAP領域はあくまで一時的な避難場所なので、使わないに越したことはありません。最近はメモリも安くなったので、メモリを惜しみなく追加しましょ う。(^^;
特にデータベースを使っている場合はなおさらです。
○ b のプロセスが多くCPU負荷が高い場合
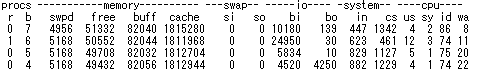
b の数値が高いのは、I/O待ちをしているプロセスが多く存在するということになります。
経験的な話ですが、b の値が5~7以上を超えている状態が長く続いたとすると、かなりI/Oディバイスに負荷がかかっていると言えるでしょう。
bi と bo の値も通常より上がっていれば、確実にディスクI/O速度が間に合っていないことになるので、RAIDやディスク回転数のアップなどを考えてもいいかもしれません。
ただ、同時にsi so が高い場合は、メモリが不足したためにSWAP領域を使ったことになり、この場合はメモリ容量をアップすることが先決です。